10 minutes
Postgres: Building concurrently safe upsert queries
Recently at the company I am working for, there was a need to communicate with an external service which required us to send some data along with an integer identifier. The problem is that IDs in our domain are not integers but uuid.
The suggestion then was to have a service which creates an unique integer for a certain uuid. This way the int identifier won’t be leaked to any other part of the system.
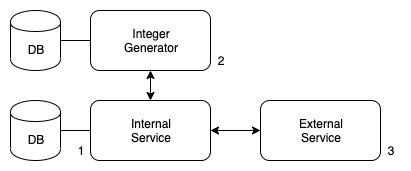
- Internal system does a request to the integer generator.
- This service will generate the int representation for certain uuid.
- Internal system does a request to external service sending the int ID.
That is fairly simple, but lets go through some more elaborated preconditions:
- For x uuid there will always be a unique y int.
- If the int representation is not created, create it.
- If the int representation is created, return it.
- The code should be concurrently safe.
In this part of the series, different approaches are being listed. For obvious reasons these ones are not based on real business. Benchmarking is going to be displayed on the next part for the approaches 3, 4 and 5.
Data Model
Just to have more context on the snippets below, the database model will be the following:
CREATE TABLE customers
(
id SERIAL,
customer_id UUID NOT NULL PRIMARY KEY
);
The approaches below are possible implementations for the integer-generator.
1. Read + write
- Receive the
POSTrequest, parse the uuid. - Execute query:
SELECT id
FROM customers
WHERE customer_id = '1796b892-c988-4f96-8eb8-a7f6f965d266'
- If the previous query returned a row, return the id.
- If not, insert the row and return the id:
INSERT INTO customers(customer_id)
VALUES('1796b892-c988-4f96-8eb8-a7f6f965d266')
RETURNING id
The problem with this approach is that if we get two consecutive calls hitting the SELECT at the same time while there is no row, both will try to add the row in the database. One will succeed and the other is going to fail.
This can be fixed changing the insert to the following:
INSERT INTO customers(customer_id)
VALUES('1796b892-c988-4f96-8eb8-a7f6f965d266')
ON CONFLICT DO NOTHING
RETURNING id
ON CONFLICT DO NOTHING will avoid the primary key exception! Yes, that is true, but when this clause does not update the row (DO NOTHING) the RETURNING row will be empty.
This can be tested by executing several times the statement in point 4.
| id |
| -- |
| 1 |
| |
| |
| |
2. Enter transaction: read + write
Same scenario than the one detailed above, but starting a transaction before executing the SELECT, and committing after the insert succeed.
Unfortunately, transaction is not going to help in any way here. The SELECT will not lock any row because no row exists and this is not exactly the way Postgres handles locking. This means that two SELECT at the same time will not cause the latest to wait until the first transaction is committed.
3. Transaction: advisory lock + read + write
- Receive the
POSTrequest, parse the uuid. - Begin the transaction:
BEGIN
- Get a lock using a numeric hash that represents x uuid in a deterministic way:
SELECT pg_advisory_xact_lock(<bigint>)
- Execute query:
SELECT id
FROM customers
WHERE customer_id = '1796b892-c988-4f96-8eb8-a7f6f965d266'
- If the previous query returned a row, return the id.
- If not, insert the row and return the id:
INSERT INTO customers(customer_id)
VALUES('1796b892-c988-4f96-8eb8-a7f6f965d266')
RETURNING id
- Commit transaction:
COMMIT
Ok, now this works. But this is still far away from a good design. In the previous approach, the race condition existed because there was nothing to lock when there was no row to be found.
In this approach, for certain uuid the same numeric hash will be generated. When starting a transaction, an exclusive transaction level advisory lock is obtained. If another transaction wants to execute the lock query using the same hash, it will have to wait until the first transaction ends with a commit or rollback.
How to try this out?
- Open a database connection.
- Execute:
BEGIN;
SELECT pg_advisory_xact_lock(12345);
- Open another database connection.
- Execute:
BEGIN;
SELECT pg_advisory_xact_lock(12345);
- This last query will not respond until the first transaction finishes.
What does this mean? It means that concurrency is being handled explicitly with locks in a way that won’t scale when having multiple requests using the same uuid.
Benchmark for this approach in part 2
4. On conflict, update
- Receive the
POSTrequest, parse the uuid. - Execute the query and return the result. This query will insert the row if it does not exist; and in case it does, it will just return the id. The update is required to return the desired id.
INSERT INTO customers(customer_id)
VALUES('1796b892-c988-4f96-8eb8-a7f6f965d266')
ON CONFLICT (customer_id)
DO UPDATE SET customer_id = excluded.customer_id
RETURNING id
The difference between the first example and this one, is that now the DO NOTHING is replaced by DO UPDATE and since an update is being executed; the returning row will never be empty. Moreover the concurrency problems are gone because they are handled by the database and not by code. This can be tested by executing several times the query.
| id |
| -- |
| 3 |
| 3 |
| 3 |
| 3 |
As simple as that. Looks great doesn’t it? Well I thought so until a colleague proved me wrong when he linked this awesome stack overflow answer .
[…] Do not update identical rows without need. Even if you see no difference on the surface, there are various side effects:
- It might fire triggers that should not be fired.
- It write-locks “innocent” rows, possibly incurring costs for concurrent transactions.
- It might make the row seem new, though it’s old (transaction timestamp).
How can one be sure that this is true? Executing the following query 5 times!
INSERT INTO customers(customer_id)
VALUES('1796b892-c988-4f96-8eb8-a7f6f965d269')
ON CONFLICT (customer_id)
DO UPDATE SET customer_id = excluded.customer_id
RETURNING ctid, xmin, xmax, id
Results:
| ctid | xmin | xmax | id |
| ----- | ---- | ---- | -- |
| (0,1) | 5876 | 0 | 2 |
| (0,2) | 5877 | 5877 | 2 |
| (0,3) | 5878 | 5878 | 2 |
| (0,4) | 5879 | 5879 | 2 |
| (0,5) | 5880 | 5880 | 2 |
What is the definition of ctid, xmin and xmax, and why do they keep increasing?
Documentation
ctid
The physical location of the row version within its table. Note that although the ctid can be used to locate the row version very quickly, a row’s ctid will change if it is updated or moved by VACUUM FULL. Therefore ctid is useless as a long-term row identifier. A primary key should be used to identify logical rows.
xmin
The identity (transaction ID) of the inserting transaction for this row version. (A row version is an individual state of a row; each update of a row creates a new row version for the same logical row.)
xmax
The identity (transaction ID) of the deleting transaction, or zero for an undeleted row version. It is possible for this column to be nonzero in a visible row version. That usually indicates that the deleting transaction hasn’t committed yet, or that an attempted deletion was rolled back.
Summary:
ctidis the tuple id composed by(page, item).xminis the creation transaction id of that row.xmaxis the destruction transaction id of that row.
In order to elaborate it is important to take into consideration the MVCC (Multiversion Concurrency Control) nature of postgres. From the Documentation :
Each SQL statement sees a snapshot of data […] regardless of the current state of the underlying data. This prevents statements from viewing inconsistent data produced by concurrent transactions performing updates on the same data rows. […] MVCC, minimizes lock contention in order to allow for reasonable performance in multiuser environments.
The main advantage of using the MVCC model of concurrency control rather than locking is […] reading never blocks writing and writing never blocks reading.
With that explained, lets introduce how an UPDATE works on postgres:
CREATE EXTENSION pageinspect;
INSERT INTO customers(customer_id)
VALUES('1796b892-c988-4f96-8eb8-a7f6f965d271');
SELECT t_ctid, t_xmin, t_xmax
FROM heap_page_items(get_raw_page('customers', 0));
| t_ctid | t_xmin | t_xmax |
| ------- | ------ | ------ |
| (0,1) | 5919 | 0 |
t_ctidindicates that the row is stored on page 0 and block 1.- The transaction id used for the creation of the row (
t_xmin) is 5919. - The destruction transaction id (
t_xmax) is 0 because no changes happened to the row.
UPDATE customers
SET customer_id = '1796b892-c988-4f96-8eb8-a7f6f965d271'
WHERE customer_id = '1796b892-c988-4f96-8eb8-a7f6f965d271'
SELECT t_ctid, t_xmin, t_xmax
FROM heap_page_items(get_raw_page('customers', 0));
| t_ctid | t_xmin | t_xmax |
| ------- | ------ | ------ |
| (0,2) | 5919 | 5920 |
| (0,2) | 5920 | 0 |
Row #1
t_ctidindicates that the row is stored on page 0 and block 2.- The transaction id used for the creation of the row (
t_xmin) is 5919. - The destruction transaction id (
t_xmax) is 5920 because the row wasDELETED.
Row #2
t_ctidindicates that the row is stored on page 0 and block 2.- The transaction id used for the creation of the row (
t_xmin) is 5920. - The destruction transaction id (
t_xmax) is 0 because no changes happened to the row.
As you can probably guess an UPDATE is a DELETE + INSERT under the hoods.
With this explained, it is confirmed why doing ON CONFLICT UPDATE is not a good choice either.
Benchmark for this approach in part 2
5. Insert first, read later
On the first approach, the problem was that the INSERT query was not updating on conflict, thus the RETURNING row is empty when the row already exists. This can be solved by flipping the order of the statements.
- Receive the
POSTrequest, parse the uuid. - Execute query:
INSERT INTO customers(customer_id)
VALUES('1796b892-c988-4f96-8eb8-a7f6f965d266')
ON CONFLICT DO NOTHING;
SELECT id
FROM customers
WHERE customer_id = '1796b892-c988-4f96-8eb8-a7f6f965d266'
It does not matter how many concurrent inserts are triggered at the same time, only the first one will get through and insert the row. Since the row is never updated (ON CONFLICT DO NOTHING) the ctid, xmin, and xmax will remain the same.
After the INSERT is executed, the SELECT statement will return the id for the recently created / already existing row.
But is this performing? For that lets EXPLAIN ANALYZE the queries:
Insert (when there is no row):
Insert on customers
Conflict Resolution: NOTHING
Tuples Inserted: 1
Conflicting Tuples: 0
Planning Time: 0.032 ms
Execution Time: 0.190 ms
Insert (when there is a conflict):
Insert on customers
Conflict Resolution: NOTHING
Tuples Inserted: 0
Conflicting Tuples: 1
-> Result
Planning Time: 0.032 ms
Execution Time: 0.244 ms
Select query:
Index Scan using customers_pkey on customers
Index Cond: (customer_id = '...'::uuid)
Planning Time: 0.069 ms
Execution Time: 0.111 ms
The summarization between the insert and the select is less than a millisecond for both cases. Don’t worry, on the next part this is proven.
Benchmark for this approach in part 2
Bonus for non Postgres users (a.k.a CTE queries)
CTE means Common Table Expression and documentation can be found here
These kind of expressions are also useful when the database engine does not support ON CONFLICT DO NOTHING.
WITH
search AS (SELECT ctid, xmax, id FROM customers WHERE customer_id = '8a57f8f4-aeed-412c-a6f6-5f9a03b17bc5' LIMIT 1),
add AS (INSERT INTO customers (customer_id) SELECT '8a57f8f4-aeed-412c-a6f6-5f9a03b17bc5' WHERE NOT EXISTS(SELECT id from search) RETURNING ctid, xmax, id)
SELECT ctid, xmax, id from add UNION ALL SELECT ctid, xmax, id from search
- Prepare the
searchstatement, it will be responsible of finding a customer given an id. - Prepare the
addstatement, it will insert the customer if it is not found on the search expression. - Execute both statements, only one will return a result.
Running EXPLAIN ANALYZE on the query:
HashAggregate
Group Key: add.ctid, add.xmax, add.id
CTE search
-> Limit
-> Index Scan using customers_pkey on customers
Index Cond: (customer_id = '...'::uuid)
CTE add
-> Insert on customers customers_1
InitPlan 2 (returns $1)
-> CTE Scan on search search_1
-> Result
One-Time Filter: (NOT $1)
-> Append
-> CTE Scan on add
-> CTE Scan on search
Planning Time: 0.256 ms
Execution Time: 2.483 ms
Benchmark for this approach in part 2
And that is all for this post. On the next post, the benchmarks for the following approaches are going to be executed:
- Advisory lock
- On conflict update
- On conflict do nothing
- CTE queries
If you consider this is useful, do not hesitate on sharing this on your favorite social media. See you next time!